GRPC 通讯的四种方式
GRPC 通讯的四种方式有
1 | service Echo { |
服务端与客户端普通的 Protobuf Message 通讯
客户端发起普通的 ProtoBuf Message, 服务端使用Stream 回应
1 | /* |
1 | /* |
- 客户端端发起 Stream 流式请求, 服务端使用 Protobuf Message 回应
1 | /* |
1 | /* |
- 客户端服务端 双向流式通讯。
1 | /* |
1 | /* |
上述完整代码 Link
GRPC 通讯的四种方式有
1 | service Echo { |
服务端与客户端普通的 Protobuf Message 通讯
客户端发起普通的 ProtoBuf Message, 服务端使用Stream 回应
1 | /* |
1 | /* |
1 | /* |
1 | /* |
1 | /* |
1 | /* |
上述完整代码 Link
在某些情况下,即使我们写了 gRPC 服务,但我们仍然想提供传统的 HTTP/JSON API。但是仅仅为了公开 HTTP/JSON API 而编写另一个服务有点不友好。
有什么方法可以只编写一次代码,却可以同时在 gRPC 和 HTTP/JSON 中提供 API?
gRPC-gateway 可以帮我们做到,它读取 protobuf service 定义并生成反向代理服务器( reverse-proxy server) ,根据服务定义中的 google.api.http annotations 将 RESTful HTTP API 转换为 gRPC。
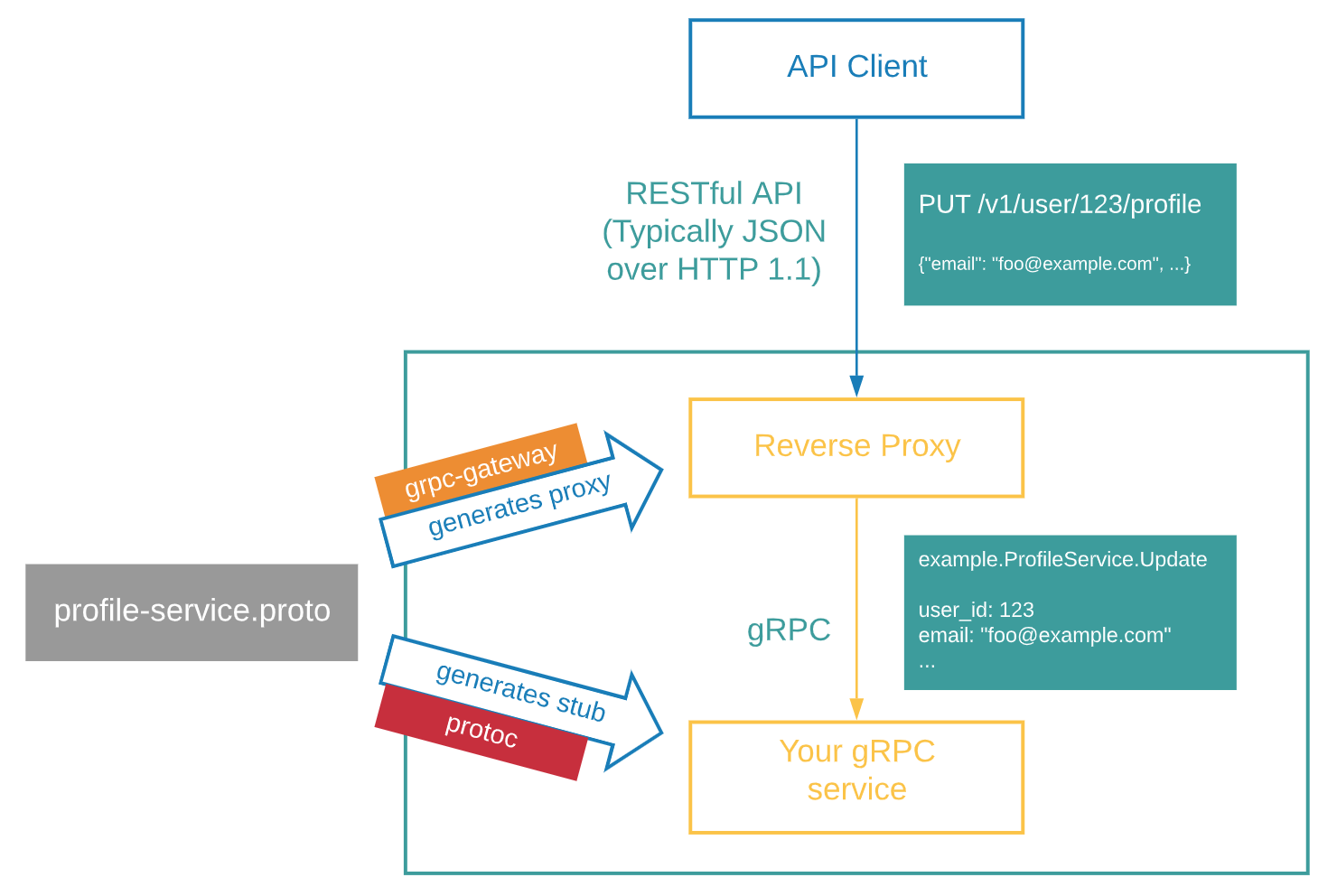
在这之前需要先安装好 protoc,
1 | sudo apt-get install protoc |
1 | |~proto/ |
在根目录执行 go mod init grpc-gateway-exp, 创建 proto 目录,从 https://github.com/googleapis/googleapis/tree/master/google/api 下载 annotation.proto 和 http.proto 放置于 proto/google/api 目录下, 主要是用于 http 服务的注解,比如:
1 | syntax = "proto3"; |
安装 buf 的命令
1 | BIN="/usr/local/bin" && \ |
在项目根目录创建 buf.yaml,buf.gen.yaml
1 | version: v1beta1 |
1 | version: v1beta1 |
执行 buf generate 之后就生成了。
项目运用了 Go Module , 以期读者何时何地的下载,都能直接使用。
项目分了子 package, 诸如 server, service, proto。
由于在根目录执行了 go mod init grpc-gateway-exp 所以对子 package 的引用, 可以用如下的写法。这个经典的写法应该引起注意。
1 | import ( |
1 | package server |
1 | curl localhost:8090/hello?message=world |
上述完整代码 Link
是一种用于存储应用所需配置信息的资源类型,用于保存配置数据的键值对,可以用来保存单个属性,也可以用来保存配置文件。
通过ConfigMap可以方便的做到配置解耦,使得不同环境有不同的配置。
下面示例创建了一个名为configmap-test的ConfigMap,ConfigMap的配置数据在data字段下定义。
1 | apiVersion: v1 |
在Volume中引用ConfigMap,就是通过文件的方式直接将ConfigMap的每条数据填入Volume,每条数据是一个文件,键就是文件名,键值就是文件内容。
如下示例中,创建一个名为vol-configmap的Volume,这个Volume引用名为“configmap-test”的ConfigMap,再将Volume挂载到容器的“/tmp”路径下。
Pod创建成功后,在容器的“/tmp”路径下,就有两个文件property_1和property_2,它们的值分别为“Hello”和“World”。
1 | apiVersion: v1 |
Secret是一种加密存储的资源对象,您可以将认证信息、证书、私钥等保存在Secret中,而不需要把这些敏感数据暴露到镜像或者Pod定义中,从而更加安全和灵活。
Secret与ConfigMap非常像,都是key-value键值对形式,使用方式也相同,不同的是Secret会加密存储,所以适用于存储敏感信息。
创建secret
1 | apiVersion: v1 |
通过文件的方式直接将Secret的每条数据填入Volume,每条数据是一个文件,键就是文件名,键值就是文件内容。
创建一个名为vol-secret的Volume,这个Volume引用名为“mysecret”的Secret,再将Volume挂载到容器的“/tmp”路径下。Pod创建成功后,在容器的“/tmp”路径下,就有两个文件key1和key2。
1 | apiVersion: v1 |
进入Pod容器中,可以在/tmp目录下发现key1和key2两个文件,并看到文件中的值是base64解码后的值,分别为“hello world”和“3306”。
Deployment集成了上线部署、滚动升级、创建副本、恢复上线的功能,在某种程度上,Deployment实现无人值守的上线,大大降低了上线过程的复杂性和操作风险。
创建一个名为nginx的Deployment负载,使用nginx:latest镜像创建两个Pod,每个Pod占用100m core CPU、200Mi内存。
1 | apiVersion: apps/v1 # 注意这里与Pod的区别,Deployment是apps/v1而不是v1 |
从这个定义中可以看到Deployment的名称为nginx,spec.replicas定义了Pod的数量,即这个Deployment控制2个Pod;spec.selector是Label Selector(标签选择器),表示这个Deployment会选择Label为app=nginx的Pod;spec.template是Pod的定义,内容与Pod中的定义完全一致。
1 | $ kubectl create -f deployment.yaml |
Deployment不是直接控制Pod的,Deployment是通过一种名为ReplicaSet的控制器控制Pod,通过如下命令可以查询ReplicaSet,其中rs是ReplicaSet的缩写。 Deployment控制ReplicaSet,ReplicaSet控制Pod。
1 | $ kubectl get rs |
如果使用kubectl describe命令查看Deployment的详情,您就可以看到ReplicaSet,如下所示,可以看到有一行NewReplicaSet: nginx-7f98958cdf (2/2 replicas created),而且Events里面事件确是把ReplicaSet的实例扩容到2个。在实际使用中您也许不会直接操作ReplicaSet
1 | $ kubectl describe deploy nginx |
在实际应用中,升级是一个常见的场景,Deployment能够很方便的支撑应用升级。
Deployment可以设置不同的升级策略,有如下两种。
1 | $ kubectl edit deploy nginx |
Deployment可以通过maxSurge和maxUnavailable两个参数控制升级过程中同时重新创建Pod的比例,这在很多时候是非常有用,配置如下所示。
1 | spec: |
回滚也称为回退,即当发现升级出现问题时,让应用回到老的版本。Deployment可以非常方便的回滚到老版本。 例如上面升级的新版镜像有问题,可以执行kubectl rollout undo命令进行回滚。
1 | $ kubectl rollout undo deployment nginx |
Deployment之所以能如此容易的做到回滚,是因为Deployment是通过ReplicaSet控制Pod的,升级后之前ReplicaSet都一直存在,Deployment回滚做的就是使用之前的ReplicaSet再次把Pod创建出来。Deployment中保存ReplicaSet的数量可以使用revisionHistoryLimit参数限制,默认值为10。
Service是基于四层TCP和UDP协议转发的,而Ingress可以基于七层的HTTP和HTTPS协议转发,可以通过域名和路径做到更细粒度的划分
要想使用Ingress功能,必须在Kubernetes集群上安装Ingress Controller。Ingress Controller有很多种实现,最常见的就是Kubernetes官方维护的NGINX Ingress Controller
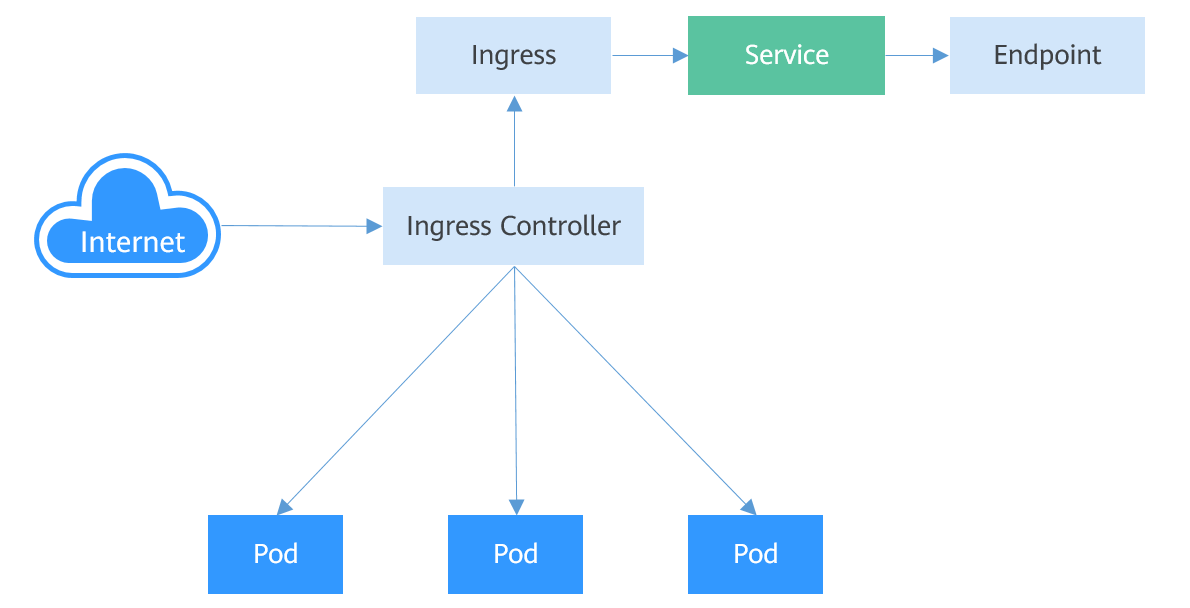
外部请求首先到达Ingress Controller,Ingress Controller根据Ingress的路由规则,查找到对应的Service,进而通过Endpoint查询到Pod的IP地址,然后将请求转发给Pod。
1 | apiVersion: networking.k8s.io/v1beta1 |
Ingress中还可以设置外部域名,这样您就可以通过域名来访问到ELB,进而访问到后端服务。
域名访问依赖于域名解析,需要您将域名解析指向ELB实例的IP地址,例如您可以使用云解析服务 DNS来实现域名解析。
Ingress可以同时路由到多个服务,配置如下所示。
1 | spec: |
Pod是Kubernetes创建或部署的最小单位。一个Pod封装一个或多个容器(container)、存储资源(volume)、一个独立的网络IP以及管理控制容器运行方式的策略选项。
Pod使用主要分为两种方式:
实际很少直接创建Pod,而是使用Kubernetes中称为Controller的抽象层来管理Pod实例,例如Deployment和Job。Controller可以创建和管理多个Pod,提供副本管理、滚动升级和自愈能力。通常,Controller 会使用Pod Template来创建相应的Pod。
如下示例描述了一个名为nginx的Pod,这个Pod中包含一个名为container-0的容器,使用nginx:alpine镜像,使用的资源为100m core CPU、200Mi内存。
1 | apiVersion: v1 # Kubernetes的API Version |
YAML描述文件主要为如下部分:
Pod定义好后就可以使用kubectl创建,如果上面YAML文件名称为nginx.yaml,则创建命令如下所示,-f表示使用文件方式创建。
1 | $ kubectl create -f nginx.yaml |
使用kubectl get命令查询具体Pod的配置信息,如下所示,-o yaml表示以YAML格式返回,还可以使用-o json,以JSON格式返回。
1 | $ kubectl get pod nginx -o yaml |
您还可以使用kubectl describe命令查看Pod的详情。
1 | $ kubectl describe pod nginx |
删除pod时,Kubernetes终止Pod中所有容器。 Kubernetes向进程发送SIGTERM信号并等待一定的秒数(默认为30)让容器正常关闭。如果它没有在这个时间内关闭,Kubernetes会发送一个SIGKILL信号杀死该进程。 Pod的停止与删除有多种方法,比如按名称删除,如下所示。
1 | $ kubectl delete po nginx |
同时删除多个Pod。
1 | $ kubectl delete po pod1 pod2 |
删除所有Pod。
1 | $ kubectl delete po --all |
根据Label删除Pod,Label详细内容将会在下一个章节介绍。
1 | $ kubectl delete po -l app=nginx |
环境变量是容器运行环境中设定的一个变量。 环境变量的使用方法如下所示,配置spec.containers.env字段即可。
1 | apiVersion: v1 |
执行如下命令查看容器中的环境变量,可以看到env_key这个环境变量,其值为env_value。
1 | $ kubectl exec -it nginx -- env |
启动容器就是启动主进程,但有些时候,启动主进程前,需要一些准备工作。比如MySQL类的数据库,可能需要一些数据库配置、初始化的工作,这些工作要在最终的MySQL服务器运行之前做完。这些操作,可以在制作镜像时通过在Dockerfile文件中设置ENTRYPOINT或CMD来完成,如下所示的Dockerfile中设置了ENTRYPOINT [“top”, “-b”]命令,其将会在容器启动时执行。
实际使用时,只需配置Pod的containers.command参数,该参数是list类型,第一个参数为执行命令,后面均为命令的参数。
1 | apiVersion: v1 |
Kubernetes提供了容器生命周期钩子,在容器的生命周期的特定阶段执行调用,比如容器在停止前希望执行某项操作,就可以注册相应的钩子函数。目前提供的生命周期钩子函数如下所示。
启动后处理(PostStart):容器启动后触发。
停止前处理(PreStop):容器停止前触发。
实际使用时,只需配置Pod的lifecycle.postStart或lifecycle.preStop参数,如下所示。
1 | apiVersion: v1 |
Label的具体形式是key-value的标记对,可以在创建资源的时候设置,也可以在后期添加和修改。
1 | apiVersion: v1 |
Pod有了Label后,在查询Pod的时候带上–show-labels就可以看到Pod的Label。
1 | $ kubectl get pod --show-labels |
1 | $ kubectl label pod nginx env=debug --overwrite |
Pod的IP地址是在Pod启动后才被分配,在启动前并不知道Pod的IP地址。 应用往往都是由多个运行相同镜像的一组Pod组成,逐个访问Pod也变得不现实。Kubernetes中的Service对象就是用来解决上述Pod访问问题的。Service有一个固定IP地址,Service将访问它的流量转发给Pod,具体转发给哪些Pod通过Label来选择,而且Service可以给这些Pod做负载均衡。
创建后台Pod首先创建一个3副本的Deployment,即3个Pod,且Pod上带有标签“app: nginx”,具体如下所示。
1 | apiVersion: apps/v1 |
创建一个名为“nginx”的Service,通过selector选择到标签“app:nginx”的Pod,目标Pod的端口为80,Service对外暴露的端口为8080。
访问服务只需要通过“服务名称:对外暴露的端口”接口,对应本例即“nginx:8080”。这样,在其他Pod中,只需要通过“nginx:8080”就可以访问到“nginx”关联的Pod。
1 | apiVersion: v1 |
将上面Service的定义保存到nginx-svc.yaml文件中,使用kubectl创建这个Service。
1 | $ kubectl create -f nginx-svc.yaml |
可以看到Service有个Cluster IP,这个IP是固定不变的,除非Service被删除,所以您也可以使用ClusterIP在集群内部访问Service。
下面创建一个Pod并进入容器,使用ClusterIP访问Pod,可以看到能直接返回内容。
1 | $ kubectl run -i --tty --image nginx:alpine test --rm /bin/sh |
通过DNS进行域名解析后,可以使用“ServiceName:Port”访问Service,这也是Kubernetes中最常用的一种使用方式。向K8s 内部 DNS查询Service的名称获得Service的IP地址。
访问时通过 ServiceName.namespace.svc.cluster.local访问,其中nginx为 Service的名称,namespace 为命名空间名称,svc.cluster.local为域名后缀,在实际使用中,在同一个命名空间下可以省略 namespace.svc.cluster.local,直接使用ServiceName即可。
例如上面创建的名为nginx的Service,直接通过“nginx:8080”就可以访问到Service,进而访问后台Pod。
使用ServiceName的方式有个主要的优点就是可以在开发应用程序时可以将ServiceName写在程序中,这样无需感知具体Service的IP地址。
前面说到有了Service后,无论Pod如何变化,Service都能够发现到Pod。
如果调用kubectl describe命令查看Service的信息,您会看下如下信息。
1 | $ kubectl describe svc nginx |
可以看到一个Endpoints,Endpoints同样也是Kubernetes的一种资源对象,可以查询得到。Kubernetes正是通过Endpoints监控到Pod的IP,从而让Service能够发现Pod。
1 | $ kubectl get endpoints |
实际上Service相关的事情都由节点上的kube-proxy处理。在Service创建时Kubernetes会分配IP给Service,同时通过API Server通知所有kube-proxy有新Service创建了,kube-proxy收到通知后通过iptables记录Service和IP/端口对的关系,从而让Service在节点上可以被查询到。
Service的类型除了ClusterIP还有NodePort、LoadBalancer和None,这几种类型的Service有着不同的用途。
NodePort类型的Service可以让Kubemetes集群每个节点上保留一个相同的端口, 外部访问连接首先访问节点IP:Port,然后将这些连接转发给服务对应的Pod。如下图所示。
1 | apiVersion: v1 |
创建并查看,可以看到PORT这一列为8080:30120/TCP,说明Service的8080端口是映射到节点的30120端口。
1 | $ kubectl create -f nodeport.yaml |
LoadBalancer类型的Service其实是NodePort类型Service的扩展,通过一个特定的LoadBalancer访问Service,这个LoadBalancer将请求转发到节点的NodePort。
1 | apiVersion: v1 |
Service解决了Pod的内外部访问问题,但还有下面这些问题没解决。
Headless Service正是解决这个问题的,Headless Service不会创建ClusterIP,并且查询会返回所有Pod的DNS记录,这样就可查询到所有Pod的IP地址。
StatefulSet中StatefulSet正是使用Headless Service解决Pod间互相访问的问题。
1 | apiVersion: v1 |
执行如下命令创建Headless Service。
1 | # kubectl create -f headless.yaml |
创建一个Pod来查询DNS,可以看到能返回所有Pod的记录,这就解决了访问所有Pod的问题了。
1 | $ kubectl run -i --tty --image tutum/dnsutils dnsutils --restart=Never --rm /bin/sh |
1 | sudo apt-get install protoc |
1 | $ export PATH="$PATH:$(go env GOPATH)/bin" |
1 | $ cd /home/levizheng/go/src/google.golang.org |
实现一个 mygrpc 的 项目, 目录树如下
1 | $:~/go/src/mygrpc>tree |
在 mygrpc 目录下 生成 proto.go, proto_grpc.pb.go
1 | mkdir helloworld; |
需要修改 helloworld_grpc.pb.go 的 package 为 helloworld, 不然后面编译不过
1 | package main |
1 | package main |
1 | cd ~/go/src/mygrpc; |
偶然在学习LRU Cache的时候,发现他原来有挺多亲戚,好奇驱动下,就一并学习,记录下来做总结。
详细实现如下
(1). 数据第一次被访问,加入到访问历史列表;
(2). 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
(3). 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
(4). 缓存数据队列中被再次访问后,重新排序;
(5). 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
工作原理当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。详细实现如下
(1). 新访问的数据插入到FIFO队列;
(2). 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;
(3). 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部
(4). 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;
(5). LRU队列淘汰末尾的数据。
是一种适应性Cache算法, 它结合了LRU与LFU。
Link 我是通过这份 golang-lru 的代码完整的学习,干净的代码读起来也欣然。
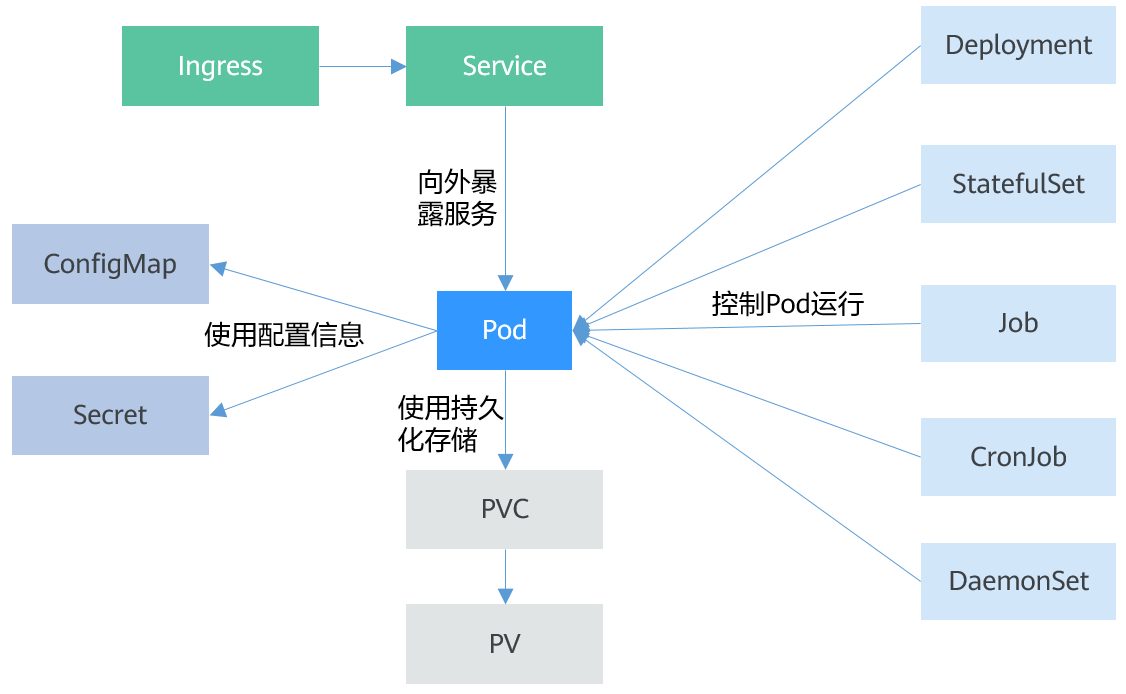
Pod
Pod是Kubernetes创建或部署的最小单位。一个Pod封装一个或多个容器(container)、存储资源(volume)、一个独立的网络IP以及管理控制容器运行方式的策略选项。
Deployment
Deployment是对Pod的服务化封装。一个Deployment可以包含一个或多个Pod,每个Pod的角色相同,所以系统会自动为Deployment的多个Pod分发请求。
StatefulSet
StatefulSet是用来管理有状态应用的对象。和Deployment相同的是,StatefulSet管理了基于相同容器定义的一组Pod。但和Deployment不同的是,StatefulSet为它们的每个Pod维护了一个固定的ID。这些Pod是基于相同的声明来创建的,但是不能相互替换,无论怎么调度,每个Pod都有一个永久不变的ID。
Job
Job是用来控制批处理型任务的对象。批处理业务与长期伺服业务(Deployment)的主要区别是批处理业务的运行有头有尾,而长期伺服业务在用户不停止的情况下永远运行。Job管理的Pod根据用户的设置把任务成功完成就自动退出(Pod自动删除)。
CronJob
CronJob是基于时间控制的Job,类似于Linux系统的crontab,在指定的时间周期运行指定的任务。
DaemonSet
DaemonSet是这样一种对象(守护进程),它在集群的每个节点上运行一个Pod,且保证只有一个Pod,这非常适合一些系统层面的应用,例如日志收集、资源监控等,这类应用需要每个节点都运行,且不需要太多实例,一个比较好的例子就是Kubernetes的kube-proxy。
Service
Service是用来解决Pod访问问题的。Service有一个固定IP地址,Service将访问流量转发给Pod,而且Service可以给这些Pod做负载均衡。
Ingress
Service是基于四层TCP和UDP协议转发的,Ingress可以基于七层的HTTP和HTTPS协议转发,可以通过域名和路径做到更细粒度的划分。
ConfigMap
ConfigMap是一种用于存储应用所需配置信息的资源类型,用于保存配置数据的键值对。通过ConfigMap可以方便的做到配置解耦,使得不同环境有不同的配置。
Secret
Secret是一种加密存储的资源对象,您可以将认证信息、证书、私钥等保存在Secret中,而不需要把这些敏感数据暴露到镜像或者Pod定义中,从而更加安全和灵活。
PersistentVolume(PV)
PV指持久化数据存储卷,主要定义的是一个持久化存储在宿主机上的目录,比如一个NFS的挂载目录。
PersistentVolumeClaim(PVC)
Kubernetes提供PVC专门用于持久化存储的申请,PVC可以让您无需关心底层存储资源如何创建、释放等动作,而只需要申明您需要何种类型的存储资源、多大的存储空间。