我的tmux
Effective
Effective
Effective
Effective
Docker
1 | int find_max_depth_V1(TreeNode* root) |
1 | int find_max_depth_V2(TreeNode* root) |
1 | int find_min_depth_V1(TreeNode* root) |
1 | int count_node(TreeNode* root) |
1 | int count_leaf_node(TreeNode* root) |
1 | int num_of_k_node(TreeNode* root, int k) |
1 | int max_depth(TreeNode* root) |
1 | bool isMirror(TreeNode* root1, TreeNode* root2) |
1 | TreeNode* mirrorTreeNode(TreeNode* root) |
1 | bool findNode(TreeNode* root, TreeNode* node) |
1 | void preOrder2(TreeNode* root, vector<int> &result) |
1 | void midOrder2(TreeNode* root, vector<int> &result) |
1 | void posOrder2(TreeNode* root, vector<int> &result) |
1 | void helper(TreeNode* root, int target, vector<int> s, int currentSum) |
[toc]
Channel 是我认为 Go 最灵活的部分,而我应用的方法不多,此文是我阅读《Go并发编程实战》总结下来,当作备忘。
可在多个 goroutine 从/往 一个Channel 中 receive/send 数据, 不必考虑额外的同步措施。Channel可以作为一个先入先出的队列,接收的数据和发送的数据的顺序是一致的。
buffered chann 满了,就会阻塞, 使用 make 分配结构空间及其附属空间,并完成其间的指针初始化, make 返回这个结构空间,不另外分配一个指针
1 | //带缓冲的Channel make |
以下代码检查是否关闭, 它可以用来检查Channel是否已经被关闭了。从Channel接收一个值,如果Channel关闭了或没有数据,那么ok将被置为false
1 | close(chan) |
在一个已经 close 的 unbuffered Channel上执行读操作,会返回Channel对应类型的零值,比如 bool 型 Channel 返回 false,int 型 Channel 返回0。
| 操作 | 空值(nil) | 已关闭 |
|---|---|---|
| 关闭 | panic | panic |
| 写 | 阻塞 | panic |
| 读 | 阻塞 | 不阻塞 |
Example
1 | package main |
select 语句和 switch 语句一样,它不是循环,它只会选择一个 case 来处理,如果想一直处理 Channel,你可以在外面加一个无限的for循环
range c 产生的迭代值为Channel中发送的值,它会一直迭代直到 Channel 被关闭。上面的例子中如果把close(c)注释掉,程序会一直阻塞在 for 那一行。
1 | for i := range c { |
1 | // 利用 time.After 实现 |
1 | main() { |
1 | // 最大并发数为 2 |
1 | func main() { |
main goroutine 通过”<-c”来等待 sub goroutine中的完成事件,sub goroutine 通过close Channel触发这一事件。当然也可以通过向 Channel 写入一个 bool 值的方式来作为事件通知。main goroutine 在 Channel c上没有任何数据可读的情况下会阻塞等待。
1 | import "fmt" |
事实上除了超时场景,其他使用协程(goroutine)的场景,也很容易因为实现不当,导致协程无法退出,随着时间的积累,造成内存耗尽,程序崩溃。
造成泄露的例子
1 | func do(taskCh chan int) { |
正确的样子
1 | func doCheckClose(taskCh chan int) { |
link: http://colobu.com/2016/04/14/Golang-Channels/
link:https://studygolang.com/articles/11320
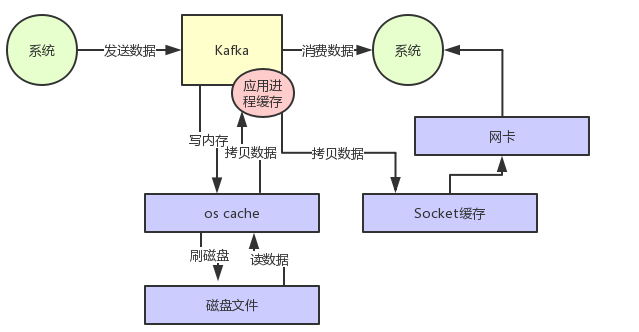
为优化读写性能,Kafka 利用操作系统本身的 Page Cache,就是利用操作系统自身的内存而不是 JVM 空间内存。
相比于使用 JVM 等数据结构,利用操作系统的 Page Cache 更加简单可靠。
如果没有零拷贝技术 Kafka 读数据的过程如下图:
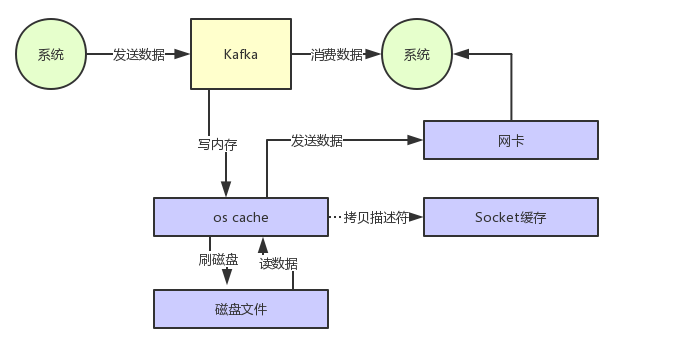
通过零拷贝技术,就不需把 os cache里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了。
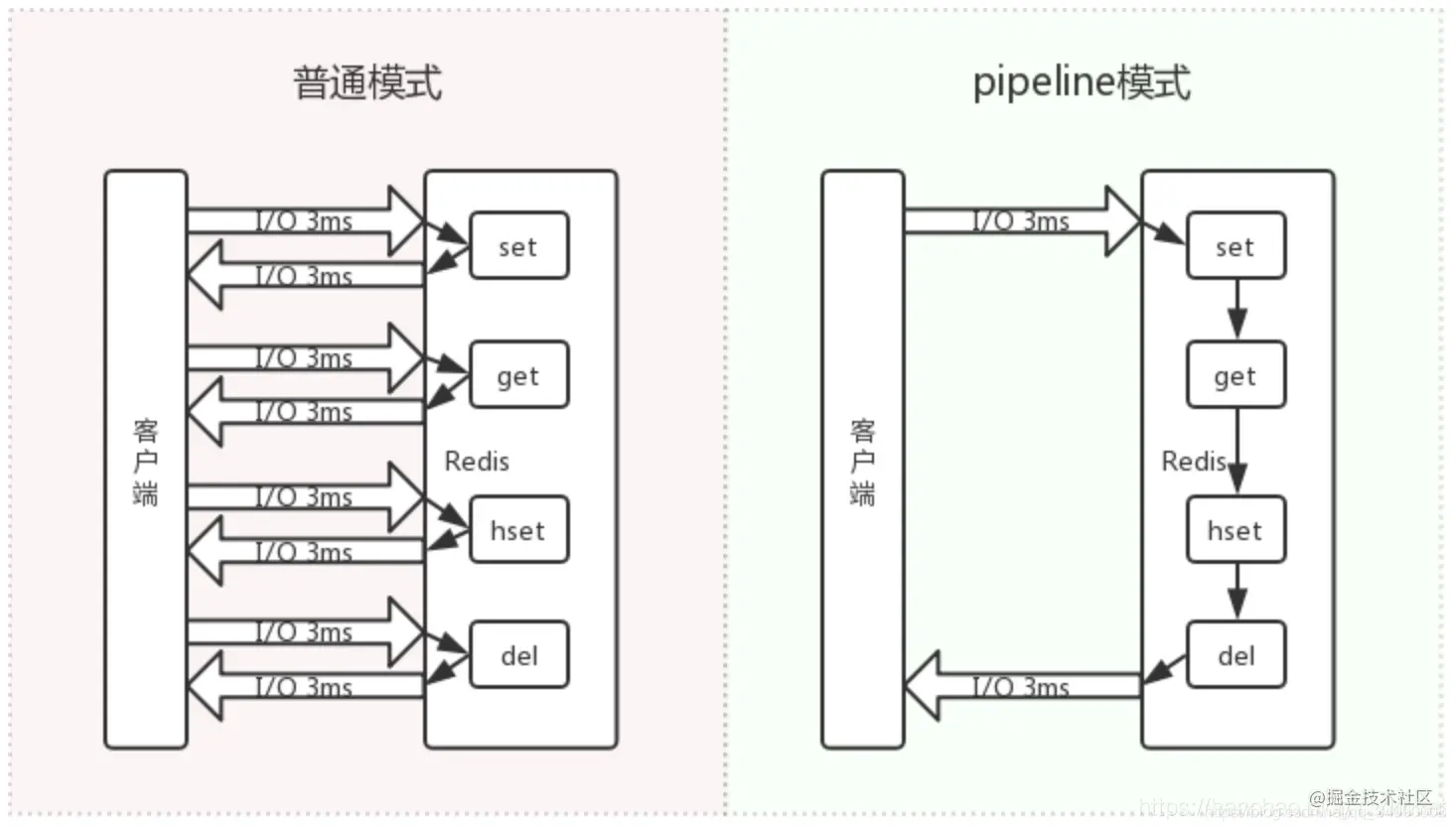
pipeline 就是把所有的命令一次发过去,避免频繁的发送、接收带来的网络开销,redis在打包接收到一堆命令后,依次执行,然后把结果再打包返回给客户端。
1 | import redis |
这容易让人想起他和MULTI有什么区别呢?
提到 watch 就离不开 Redis 事务,Redis 事务可以一次执行多个命令,它先以 MULTI 开始一个事务,然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令。
在 Redis 中使用 watch 命令可以决定事务是执行还是回滚。在 multi 命令之前使用 watch 命令监控某些键值对,然后使用 multi 命令开启事务,执行各类对数据结构进行操作的命令,这个时候命令会进入队列。 当 Redis 使用 exec 命令执行事务的时候
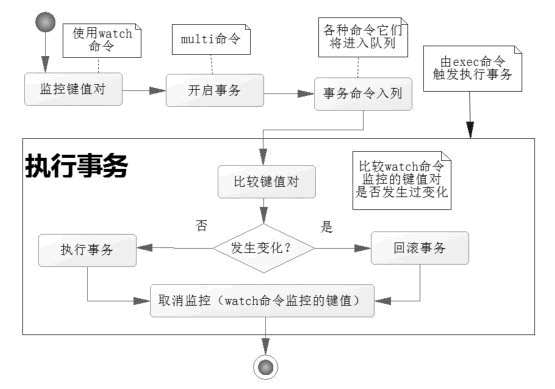
Pipeline 加上 watch, 实现事务。
1 | import redis |
RocketMQ 是阿里巴巴消息中间件团队研发并大规模应用于生产系统的中间件,满足线上海量消息堆积的需求,早期阿里曾经基于ActiveMQ研发消息系统,随着业务消息的规模增大,瓶颈逐渐显现,后来也考虑过Kafka,但因为在低延迟和高可靠性方面没有选择,最后才自主研发了RocketMQ, 各方面的性能都比目前已有的消息队列要好,RocketMQ和Kafka在概念和原理上都非常相似,所以也经常被拿来对比;RocketMQ默认采用长轮询的拉模式, 单机支持千万级别的消息堆积,可以非常好的应用在海量消息系统中。
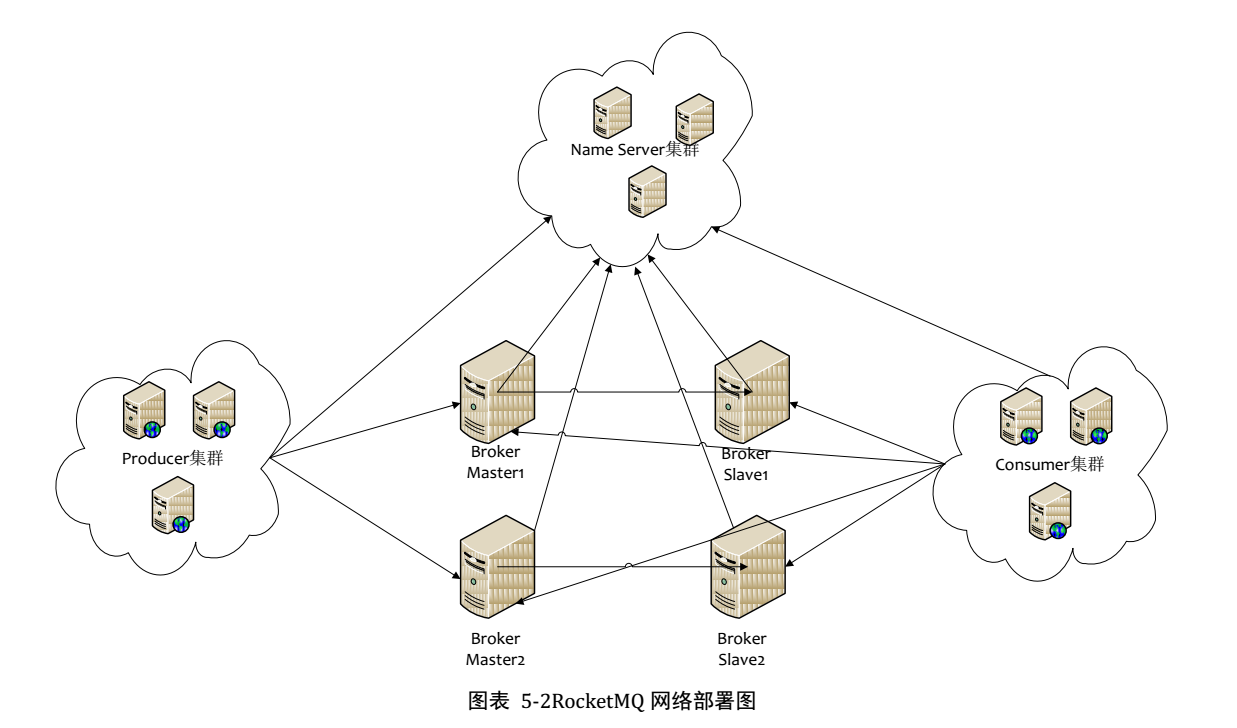
主要组成包括 NameServer, Broker, Producer, Consumer
RocketMQ 自研了类似于 zookeeper 的一个软件, 我觉得是因为功能简单,就没有引入zookeeper了, 其主要功能:
为帮助理解,先上概念图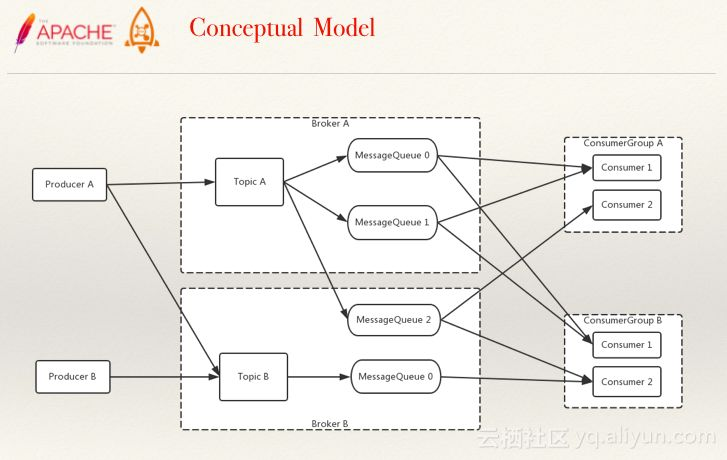
Broker上存Topic信息,Topic由多个队列组成,队列会平均分散在多个Broker上。Producer的发送机制保证消息尽量平均分布到所有队列中,最终效果就是所有消息都平均落在每个 Broker 上。
CommitLog:是消息主体以及元数据的存储主体,对 CommitLog 建立一个ConsumeQueue,每个 ConsumeQueue 对应一个(概念模型中的)MessageQueue,所以只要有 CommitLog 在,ConsumeQueue即使数据丢失,仍然可以恢复出来。
ConsumeQueue:是一个消息的逻辑队列,存储了这个 Queue 在 CommitLog 中的起始 offset,log 大小和 MessageTag的hashCode。每个Topic下的每个 Queue 都有一个对应的 ConsumeQueue 文件,例如Topic中有三个队列,每个队列中的消息索引都会有一个编号,编号从0开始,往上递增。并由此一个位点offset的概念。
RocketMQ的高性能在于顺序写盘(CommitLog)、零拷贝和跳跃读, 尽量命中PageCache, 所以内存越大越好。同时由于缓存的局部性原理,可以很快的在内存上读取到消息。
高可靠性在于刷盘和 Master/Slave,即使 NameServer 全部挂掉不影响已经运行的 Broker,Producer,Consumer。
发送消息可负载均衡,且发送消息线程安全,集群消费模式下消费者端负载均衡,这些特性加上上述的高性能读写,共同造就了 RocketMQ 的高并发读写能力。
刷盘和主从同步均为异步(默认)时,broker进程挂掉(例如重启),消息依然不会丢失,因为 broker 关机时会执行持久化。 当物理机器宕机时,才有消息丢失的风险。另外,master挂掉后,消费者从slave消费消息,但slave不能写消息。
RocketMQ具有很好动态伸缩能力(非顺序消息),伸缩性体现在Topic和Broker两个维度。
Topic维度:假如一个Topic的消息量特别大,但集群水位压力还是很低,就可以扩大该Topic的队列数,Topic的队列数跟发送、消费速度成正比。
Broker维度:如果集群水位很高了,需要扩容,直接加机器部署Broker就可以。Broker 起来后向 NameServer 注册,Producer、Consumer 通过 NameServer 发现新 Broker,立即跟该Broker直连,收发消息。
RocketMQ事务消息
指的是暂不能投递的消息,发送方已经将消息成功发送到了 MQ 服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成 “暂不能投递”状态,处于该种状态下的消息即半消息。
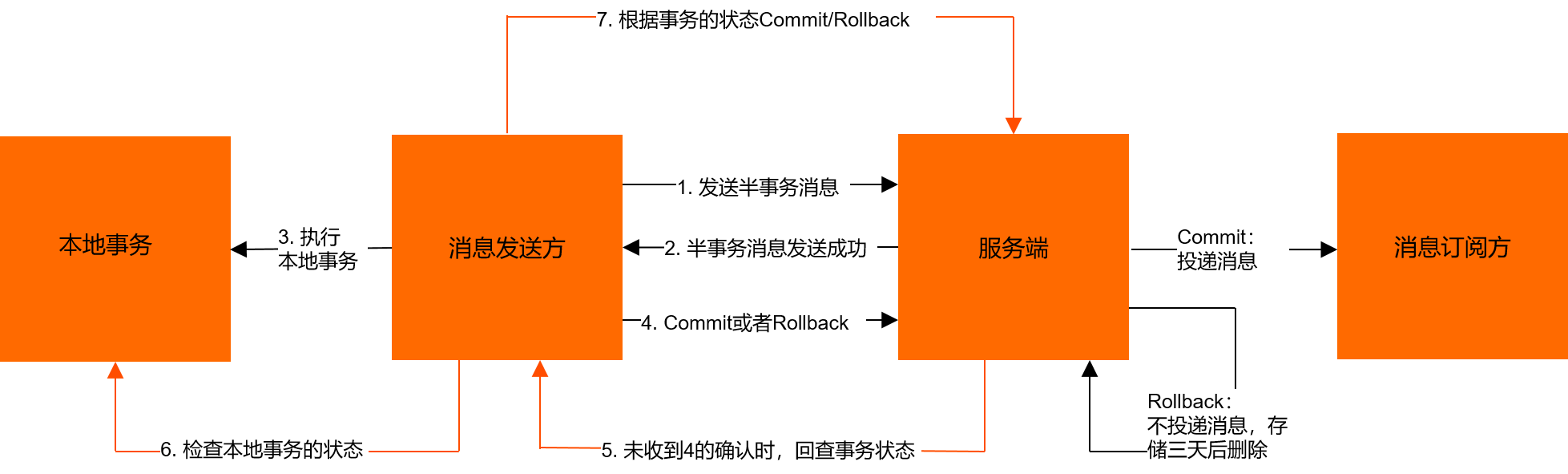
采用的是长轮询方式
当业务需要系统间调用解耦时,MQ 是一个很好的方案,目前选择最多的当属Kafka和阿里的RocketMQ, 两种中间件的对比屡屡被提及。
适用场景
Kafka适合日志处理; RocketMQ适合业务处理。
性能
Kafka单机写入 TPS 号称在百万条/秒; RocketMQ 大约在10万条/秒。 追求性能的话,Kafka单机性能更高。
可靠性
RocketMQ 支持异步/同步刷盘; 异步/同步 Replication; Kafka使用异步刷盘方式,异步Replication。 RocketMQ所支持的同步方式提升了数据的可靠性。
支持的队列数
Kafka单机超过64个队列/分区,消息发送性能降低严重; RocketMQ 单机支持最高5万个队列,性能稳定, 这也是适合业务处理的原因之一
消费失败重试机制
Kafka消费失败不支持重试, RocketMQ消费失败支持定时重试,每次重试间隔时间顺延。
定时消息
Kafka不支持定时消息, RocketMQ支持定时消息
分布式事务消息
Kafka不支持分布式事务消息, RocketMQ支持分布式事务消息
消息查询机制
Kafka不支持消息查询, RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息
消息回溯
Kafka 理论上可以按照 Offset 来回溯消息, RocketMQ 支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息
GTID 是基于 MySQL 服务器生成的已经被成功执行的全局事务ID,由服务器ID以及事务ID组合而成。这个全局ID在所有存在主从关系的数据库服务器上是唯一的。这样特性使 MySQL 的主从复制变得更加简单,以及数据库一致性更可靠。
MySQL-5.6.5开始支持GTID。 global transaction identifiers。全局唯一ID。
一个GTID在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
GTID用来代替传统复制方法,不再使用 MASTER_LOG_FILE 与 MASTER_LOG_POS 开启复制。而是使用 MASTER_AUTO_POSTION=1 的方式开始复制。
1、更简单搭建主从, 不用以前那样在需要找log_file和log_pos。
2、比传统的复制更加安全,保证数据的一致性,零丢失。
1 当一个事务在主库端执行并提交时,产生GTID,记录到 binlog 。
2 binlog 传输到 slave, 存储到 slave 的 relaylog 后,设置gtid_next变量,告诉 slave,下一个要执行的 GTID 值。
3 SQL 线程从 relay log中获取GTID,然后对比 slave的 binlog 是否有该GTID。
4 如果有记录,说明该 GTID 的事务已经执行,slave 会忽略。
5 如果没有记录,slave 就会执行该 GTID 事务,并记录该 GTID 到自身的 binlog, 在执行事务前会先检查其他 session 持有该GTID,确保不被重复执行。
6 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。
对于 GTID 的配置(使用mysql-5.6.5以上版本),如下:
1 | [mysqld] |
1 | [mysqld] |
1 | [master]> CHANGE MASTER TO |
按上文修改配置参数文件;
所有服务器设置global.read_only参数,等待主从服务器同步完毕;
1 | mysql> SET @@global.read_only = ON; |
依次重启主从服务器;
使用change master 更新主从配置;
1 | mysql> CHANGE MASTER TO |