Kafka 吞吐量大的原因
Page Cache
为优化读写性能,Kafka 利用操作系统本身的 Page Cache,就是利用操作系统自身的内存而不是 JVM 空间内存。
- 避免 Object 消耗:如果是使用 Java 堆,Java对象的内存消耗比较大,通常是所存储数据的两倍甚至更多。
- 避免 GC问题:随着 JVM 中数据不断增多,垃圾回收将会变得复杂与缓慢,使用系统缓存就不会存在 GC 问题
相比于使用 JVM 等数据结构,利用操作系统的 Page Cache 更加简单可靠。
- 操作系统层面的缓存利用率会更高,因为存储的都是紧凑的字节结构而不是独立的对象。
- 即使服务进程重启,系统缓存依然不会消失,避免了重建缓存的过程。
零拷贝
如果没有零拷贝技术 Kafka 读数据的过程如下图:
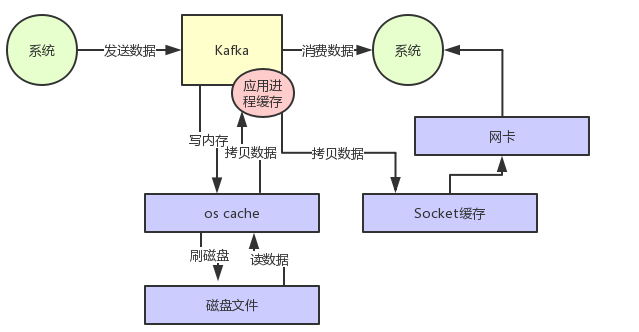
- 先看数据在不在 os cache里,如果不在的话就从磁盘文件里读取数据后放入 os cache。
- 从操作系统的 os cache 里拷贝数据到应用程序进程的缓存里,
- 从应用程序进程的缓存里拷贝数据到操作系统层面的 Socket 缓存里,
- 从Socket缓存里提取数据后发送到网卡,最后发送出去给下游消费。
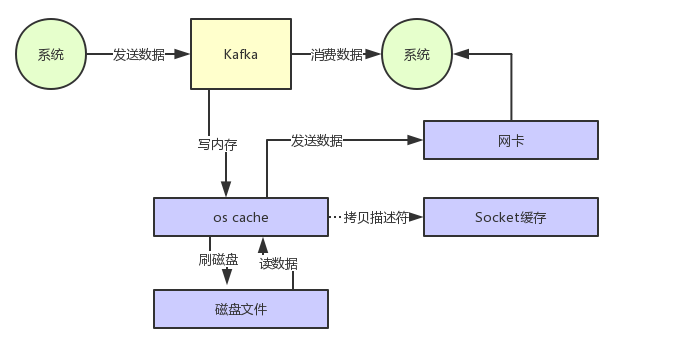
通过零拷贝技术,就不需把 os cache里的数据拷贝到应用缓存,再从应用缓存拷贝到 Socket 缓存了,两次拷贝都省略了。
- 对 Socket 缓存仅仅就是拷贝数据的描述符过去,然后数据就直接从 os cache 中发送到网卡上去了,大大的提升数据消费时读取文件数据的性能。
- 在从磁盘读数据的时候,会先看看 os cache 内存中是否有,如果有的话,其实读数据都是直接读内存的。
- 大量的数据都是直接写入 os cache 中,然后读数据的时候也是从 os cache 中读。 相当于是 Kafka 完全基于内存提供数据的写和读了,所以这个整体性能会极其的高。
分区分段+索引
- Kafka 的 message 是按 topic 分类存储的,
- topic 中的数据按照一个一个的 partition 即分区存储到不同broker节点。
- 每个 partition 对应了操作系统上的一个文件夹,partition 实际上又是按照 segment 分段存储的。Kafka 的 message 消息实际上是分布式存储在一个一个小的 segment 中的,每次文件操作也是直接操作的 segment。
- Kafka 又默认为分段后的数据文件建立了索引文件,就是文件系统上的.index文件。这种分区分段+索引的设计,不仅提升了数据读取的效率,同时也提高了数据操作的并行度。
磁盘顺序写, 批量读写, 批量压缩
- 消息是顺序写磁盘的
- Kafka 数据读写也是批量的而不是单条的。 除了利用底层的技术外,Kafka 还在应用程序层面提供了一些手段来提升性能。最明显的就是使用批次。在向Kafka写入数据时,可以启用批次写入,这样可以避免在网络上频繁传输单个消息带来的延迟和带宽开销