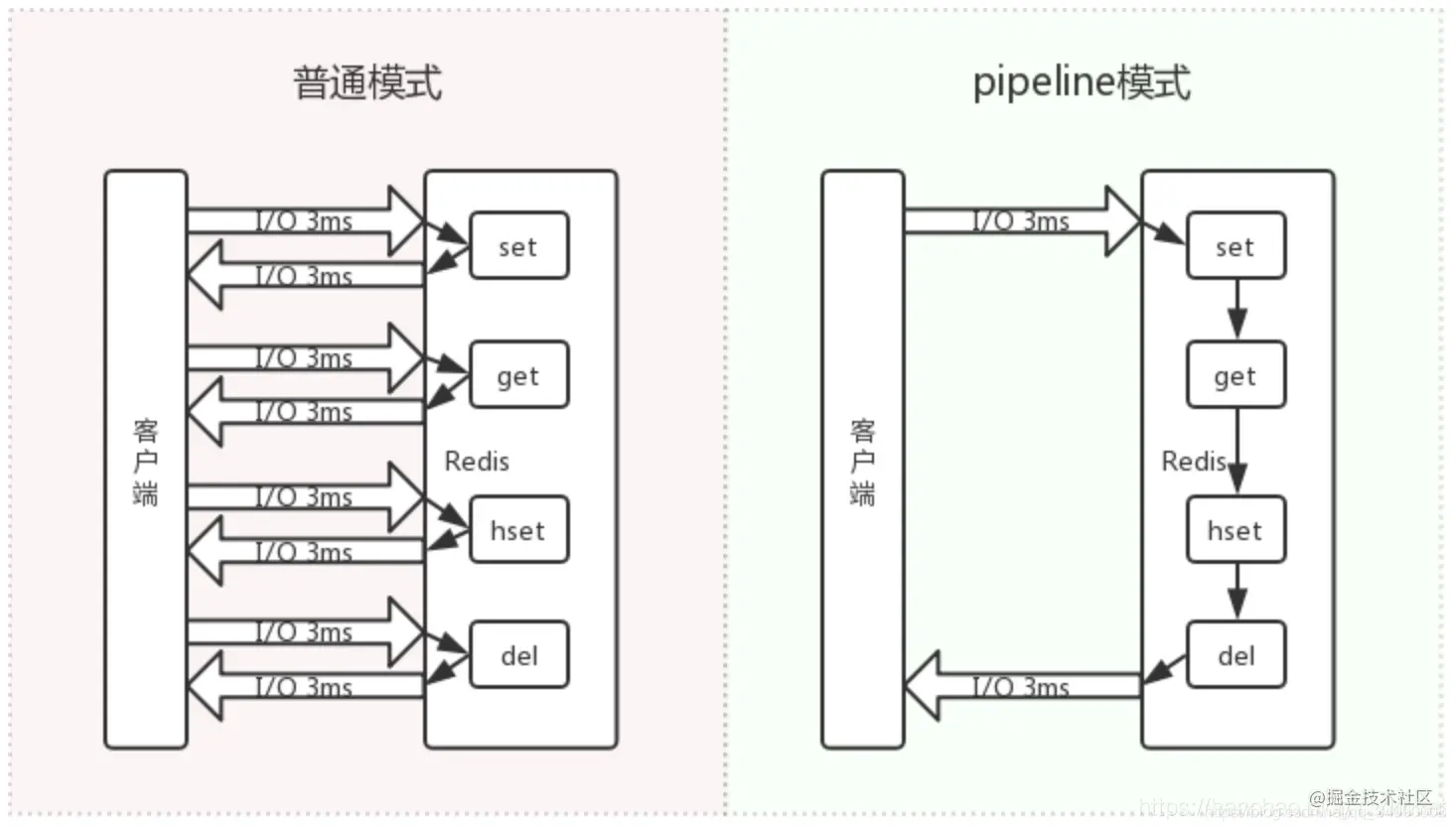
pipline 是什么 pipeline 就是把所有的命令一次发过去,避免频繁的发送、接收带来的网络开销,redis在打包接收到一堆命令后,依次执行,然后把结果再打包返回给客户端。
1 2 3 4 5 6 7 8 9 10 import redis from concurrent.futures import ProcessPoolExecutor r = redis.Redis(host='127.0.0.1', port=6380) if __name__ == "__main__": with r.pipeline(transaction=False) as p: p.sadd('seta', 1) p.sadd('seta', 2) p.execute()
这容易让人想起他和MULTI有什么区别呢?
pipeline 选择客户端缓冲,multi 选择服务端队列缓冲;
请求次数的不一致,multi需要每个命令都发送一次给服务端,pipeline最后一次性发送给服务端,请求次数相对于multi减少
multi/exec 可以保证原子性,而 pipeline 不保证原子性
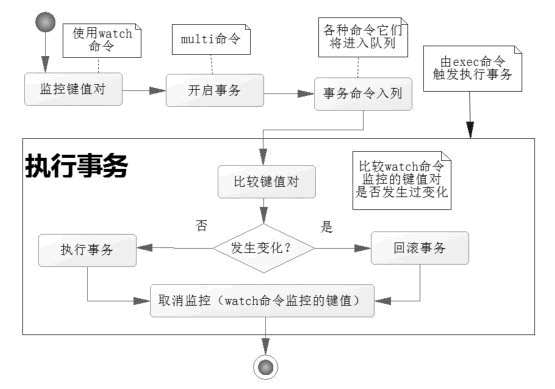
watch 是什么 提到 watch 就离不开 Redis 事务,Redis 事务可以一次执行多个命令,它先以 MULTI 开始一个事务,然后将多个命令入队到事务中, 最后由 EXEC 命令触发事务, 一并执行事务中的所有命令。
它首先去比对被 watch 命令所监控的键值对,如果没有发生变化,那么它会执行事务队列中的命令,提交事务;
如果发生变化,那么它不会执行任何事务中的命令,而去事务回滚。无论事务是否回滚,Redis 都会去取消执行事务前的 watch 命令
Pipeline 加上 watch, 实现事务。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import redis from concurrent.futures import ProcessPoolExecutor r = redis.Redis(host='127.0.0.1', port=6379) r.set("stock:count", 100) if __name__ == "__main__": with r.pipeline() as pipe: while True: try: # watch库存键, multi后如果该key被其他客户端改变, 事务操作会抛出WatchError异常 pipe.watch('stock:count') count = int(pipe.get('stock:count')) if count > 0: # 有库存 # 事务开始 pipe.multi() # pipe.decr('stock:count') # 把命令推送过去 return True else: return False except redis.WatchError: # 打印WatchError异常, 观察被watch锁住的情况 pipe.unwatch()