RocketMQ
RocketMQ 是阿里巴巴消息中间件团队研发并大规模应用于生产系统的中间件,满足线上海量消息堆积的需求,早期阿里曾经基于ActiveMQ研发消息系统,随着业务消息的规模增大,瓶颈逐渐显现,后来也考虑过Kafka,但因为在低延迟和高可靠性方面没有选择,最后才自主研发了RocketMQ, 各方面的性能都比目前已有的消息队列要好,RocketMQ和Kafka在概念和原理上都非常相似,所以也经常被拿来对比;RocketMQ默认采用长轮询的拉模式, 单机支持千万级别的消息堆积,可以非常好的应用在海量消息系统中。
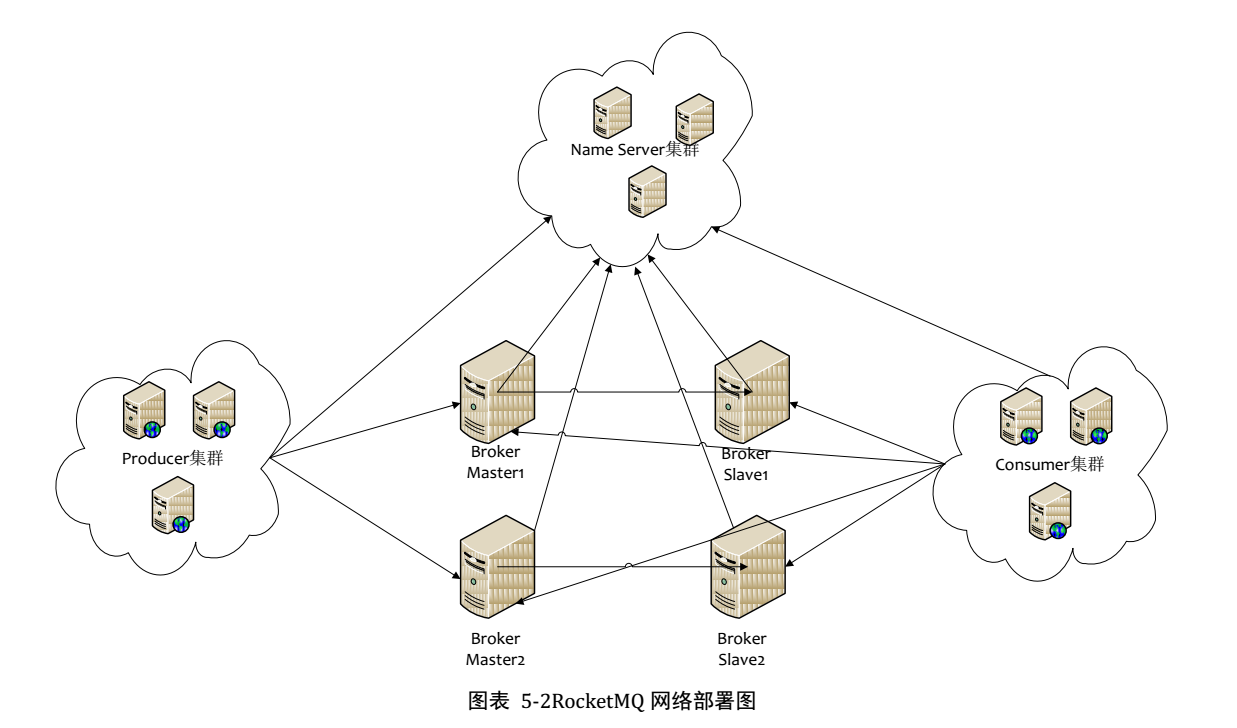
主要组成包括 NameServer, Broker, Producer, Consumer
NameServer
RocketMQ 自研了类似于 zookeeper 的一个软件, 我觉得是因为功能简单,就没有引入zookeeper了, 其主要功能:
- 管理brokers:broker 启动时会注册到 NameServer,两者之间保持心跳监测机制,来保证 NameServer 知道 broker 的存活状态
- 路由信息管理:每一台 NameServer 存有全部的 broker 集群信息和生产者/消费者客户端的请求信息
为帮助理解,先上概念图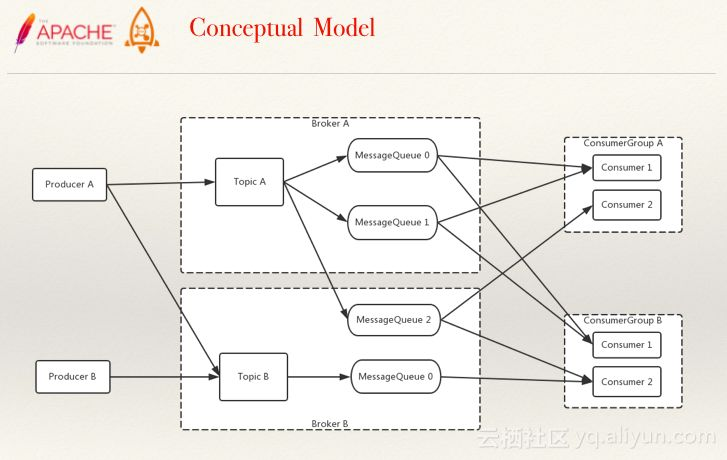
Broker
Broker上存Topic信息,Topic由多个队列组成,队列会平均分散在多个Broker上。Producer的发送机制保证消息尽量平均分布到所有队列中,最终效果就是所有消息都平均落在每个 Broker 上。
CommitLog:是消息主体以及元数据的存储主体,对 CommitLog 建立一个ConsumeQueue,每个 ConsumeQueue 对应一个(概念模型中的)MessageQueue,所以只要有 CommitLog 在,ConsumeQueue即使数据丢失,仍然可以恢复出来。
ConsumeQueue:是一个消息的逻辑队列,存储了这个 Queue 在 CommitLog 中的起始 offset,log 大小和 MessageTag的hashCode。每个Topic下的每个 Queue 都有一个对应的 ConsumeQueue 文件,例如Topic中有三个队列,每个队列中的消息索引都会有一个编号,编号从0开始,往上递增。并由此一个位点offset的概念。
RocketMQ的高性能在于顺序写盘(CommitLog)、零拷贝和跳跃读, 尽量命中PageCache, 所以内存越大越好。同时由于缓存的局部性原理,可以很快的在内存上读取到消息。
高可靠性高性能
高可靠性在于刷盘和 Master/Slave,即使 NameServer 全部挂掉不影响已经运行的 Broker,Producer,Consumer。
发送消息可负载均衡,且发送消息线程安全,集群消费模式下消费者端负载均衡,这些特性加上上述的高性能读写,共同造就了 RocketMQ 的高并发读写能力。
刷盘和主从同步均为异步(默认)时,broker进程挂掉(例如重启),消息依然不会丢失,因为 broker 关机时会执行持久化。 当物理机器宕机时,才有消息丢失的风险。另外,master挂掉后,消费者从slave消费消息,但slave不能写消息。
动态伸缩能力
RocketMQ具有很好动态伸缩能力(非顺序消息),伸缩性体现在Topic和Broker两个维度。
Topic维度:假如一个Topic的消息量特别大,但集群水位压力还是很低,就可以扩大该Topic的队列数,Topic的队列数跟发送、消费速度成正比。
Broker维度:如果集群水位很高了,需要扩容,直接加机器部署Broker就可以。Broker 起来后向 NameServer 注册,Producer、Consumer 通过 NameServer 发现新 Broker,立即跟该Broker直连,收发消息。
事务消息机制
RocketMQ事务消息
- Half(Prepare) Message
指的是暂不能投递的消息,发送方已经将消息成功发送到了 MQ 服务端,但是服务端未收到生产者对该消息的二次确认,此时该消息被标记成 “暂不能投递”状态,处于该种状态下的消息即半消息。
- 消息回查
由于网络闪断、生产者应用重启等原因,导致某条事务消息的二次确认丢失,MQ 服务端通过扫描发现某条消息长期处于“半消息”时,需要主动向消息生产者询问该消息的最终状态(Commit 或是 Rollback),该过程即消息回查。
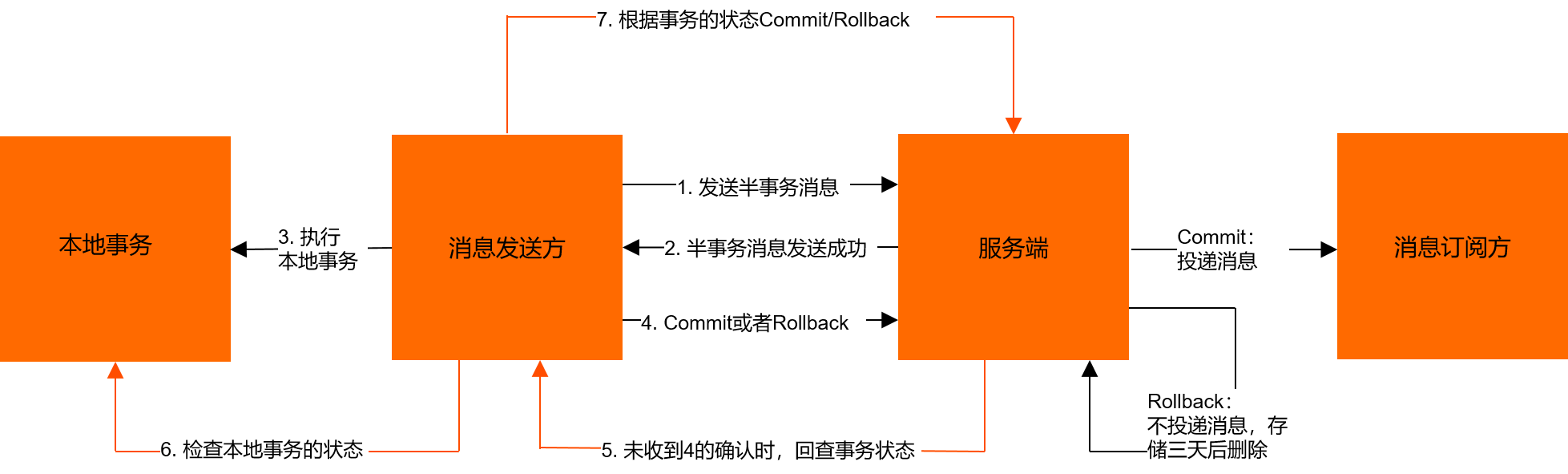
- 发送方向 MQ 服务端发送消息。
- MQ Server 将消息持久化成功之后,向发送方 ACK 确认消息已经发送成功,此时消息为半消息。
- 发送方开始执行本地事务逻辑。
- 发送方根据本地事务执行结果向 MQ Server 提交二次确认(Commit 或是 Rollback),MQ Server 收到 Commit 状态则将半消息标记为可投递,订阅方最终将收到该消息;MQ Server 收到 Rollback 状态则删除半消息,订阅方将不会接受该消息。
- 在断网或者是应用重启的特殊情况下,上述步骤4提交的二次确认最终未到达 MQ Server,经过固定时间后 MQ Server 将对该消息发起消息回查。
- 发送方收到消息回查后,需要检查对应消息的本地事务执行的最终结果。
- 发送方根据检查得到的本地事务的最终状态再次提交二次确认,MQ Server 仍按照步骤4对半消息进行操作。
关于 Consumer
采用的是长轮询方式
- CLUSTERING 模式下,一条消息只会被 ConsumerGroup 里的一个实例消费,但可以被多个不同的 ConsumerGroup 消费,
- BROADCASTING 模式下,一条消息会被ConsumerGroup里的所有实例消费。
Kafka 与 RocketMQ 对比:
当业务需要系统间调用解耦时,MQ 是一个很好的方案,目前选择最多的当属Kafka和阿里的RocketMQ, 两种中间件的对比屡屡被提及。
适用场景
Kafka适合日志处理; RocketMQ适合业务处理。性能
Kafka单机写入 TPS 号称在百万条/秒; RocketMQ 大约在10万条/秒。 追求性能的话,Kafka单机性能更高。可靠性
RocketMQ 支持异步/同步刷盘; 异步/同步 Replication; Kafka使用异步刷盘方式,异步Replication。 RocketMQ所支持的同步方式提升了数据的可靠性。支持的队列数
Kafka单机超过64个队列/分区,消息发送性能降低严重; RocketMQ 单机支持最高5万个队列,性能稳定, 这也是适合业务处理的原因之一消费失败重试机制
Kafka消费失败不支持重试, RocketMQ消费失败支持定时重试,每次重试间隔时间顺延。定时消息
Kafka不支持定时消息, RocketMQ支持定时消息分布式事务消息
Kafka不支持分布式事务消息, RocketMQ支持分布式事务消息消息查询机制
Kafka不支持消息查询, RocketMQ支持根据Message Id查询消息,也支持根据消息内容查询消息消息回溯
Kafka 理论上可以按照 Offset 来回溯消息, RocketMQ 支持按照时间来回溯消息,精度毫秒,例如从一天之前的某时某分某秒开始重新消费消息