几个星期之前还和@huangSir 说起了Golang支持了这”B格高”的玩意。跳表可以在列表中的查找可以快速的跳过部分列表,效率高.故名思义,过年这几天阅读Leveldb源码的时候,memtable也用了这玩意
跳表简介
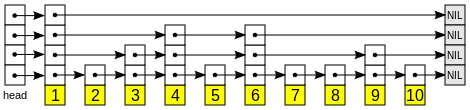
Skip List是
- 一种随机化的数据结构,基于并联的链表,
- 其效率可比拟于二叉查找树(对于大多数操作需要O(log n)平均时间)。
- 以空间换时间,对有序的链表随机化增加上附加的前进链接
- 由多层链表组成,每一层有序的链表,第一层包含所有的元素;
数据结构
1
2
3
4
5
| struct node {
int key;
int value;
node *next[1];
}
|
其中nodec * next[1] 是该节点的前向指针
1
2
3
4
5
| struct skiplist
{
int level;
node *header;链表头
};
|
通常一个数据结构我们定义为表头信息和最大的层数
列表的初始化需要初始化头部,并使头部每层都指向末尾(NULL)。MAX_LEVEL是我们定义的常量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| node *createNode(int level, int key, int value) {
node *ns = (node *) malloc(sizeof(node) + level * sizeof(node*));
ns->key = key;
ns->value = value;
return ns;
}
skiplist* createSkiplist() {
skiplist *sl = (skiplist *)malloc(sizeof(skiplist));
sl->level = 0;
sl->header = createNode(MAX_LEVEL-1,0,0);
for(int i=0; i<MAX_LEVEL; i++) {
sl->header->next[i] = NULL;
}
return sl;
}
|
插入元素的时候元素所占有的层数完全是随机的,通过随机算法产生 需要三个步骤:
- 第一步需要查找到在每层待插入位置,
- 然后需要随机产生一个层数,
- 最后就是从高层至下插入.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| bool insert(skiplist *sl,int key,int value) {
node *update[MAX_LEVEL];
node *p, *q = NULL;
p = sl->header;
int k = sl->level;
for(int i = k-1; i >= 0; i--) {
while((q = p->next[i]) && (q->key<key)) {
p = q;
}
update[i]=p;
}
if(q && q->key == key) return false;
//产生一个随机层数K,新建一个待插入节点q, 层层插入
k = randomLevel();
//更新跳表的level
if(k > (sl->level)) {
for(int i = sl->level; i < k; i++){
update[i] = sl->header;
}
sl->level = k;
}
q = createNode(k, key, value);
//逐层更新节点的指针,和普通列表插入一样
for(int i = 0;i<k;i++)
{
q->next[i] = update[i]->next[i];
update[i]->next[i] = q;
}
return true;
}
|
与插入类似的是,为了实现层层操作,用一个update数组维护每层需要的节点,如果删掉最大层则需要更新跳表的level。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| bool deleteSL(skiplist *sl,int key) {
node *update[MAX_LEVEL];
node *p,*q = NULL;
p = sl->header;
int k=sl->level;
for(int i = k-1; i >= 0; i--){
while((q = p->next[i]) && (q->key<key)) {
p = q;
}
update[i] = p;
}
if(q && q->key == key) {
for(int i = 0; i<sl->level; i++){
if(update[i]->next[i] == q){
update[i]->next[i] = q->next[i];
}
}
free(q);
for(int i=sl->level-1; i >= 0; i--){
if(sl->header->forward[i]==NULL){
sl->level--;
}
}
return true;
}
else
return false;
}
|
从最高层查找起, 跳跃查找
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| int search(skiplist * sl, int key) {
node * p, *q = NULL;
p = sl->header;
int k = sl->level;
for (int i = k-1; i >= 0; i--) {
while ((q = p->forward[i]) && q->key <= key) {
if (q->key == key) {
return q->value;
}
p = q;
}
}
return NULL;
}
|
应用场景
如前面说道的,老夫在leveldb的memtable.c看到这一实现的, Redis也是用到了这样的设计,看来KV的设计对skiplist有偏好,leveldb需要内存中存储的是有序的key-val键值对, 作为一个内存数据库,快速是很重要的,特别是数据量大的时候。牺牲了部分空间(冗余的指针)换取时间,达到O(logn)的效果
引用资料
- [wikipedia](http://zh.wikipedia.org/wiki/%E8%B7%B3%E8%B7%83%E5%88%97%E8%A1%A8)
- [skiplist讲解](http://blog.csdn.net/ict2014/article/details/17394259)
- [source code](https://github.com/zheng-ji/ToyCollection/skiplist)